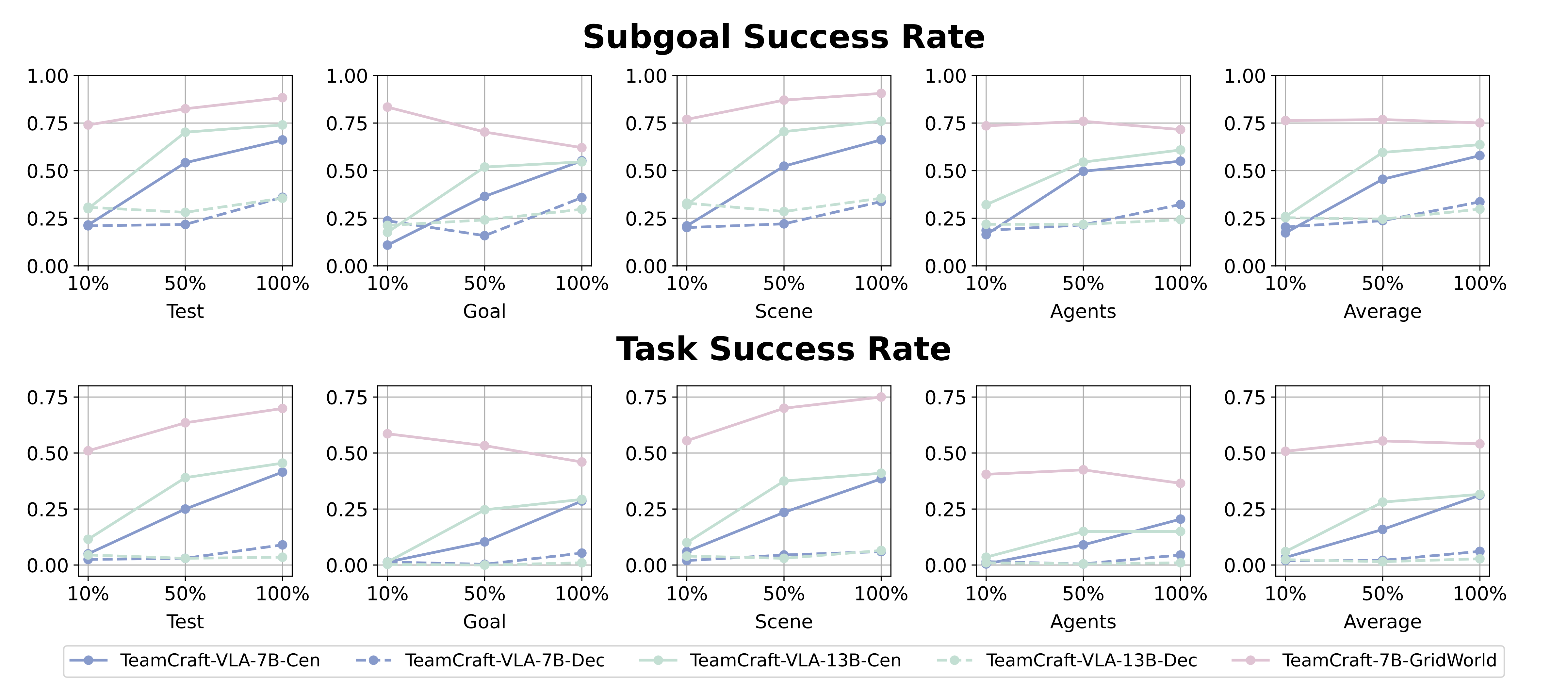
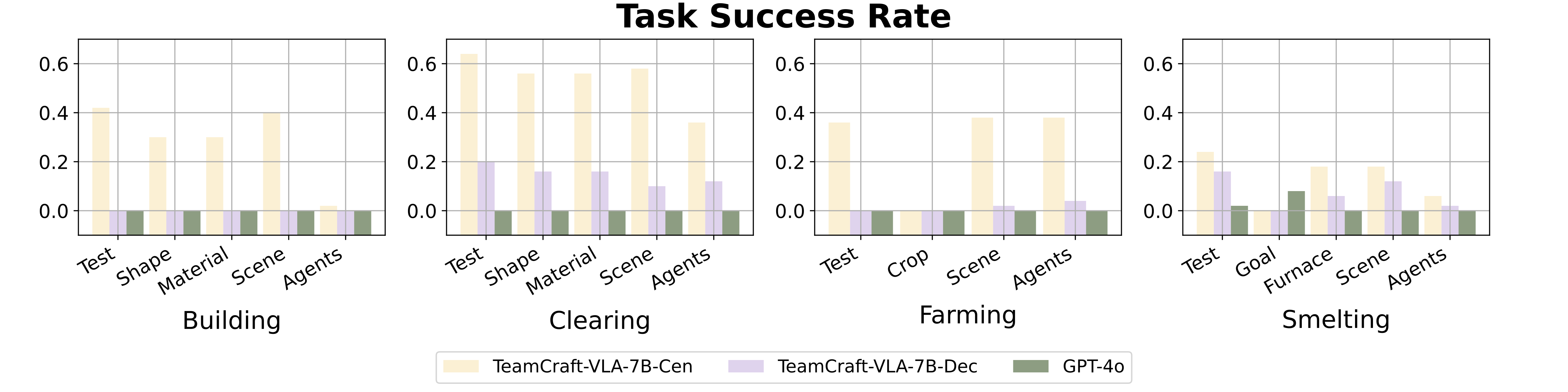
Multi-modal VLA Model
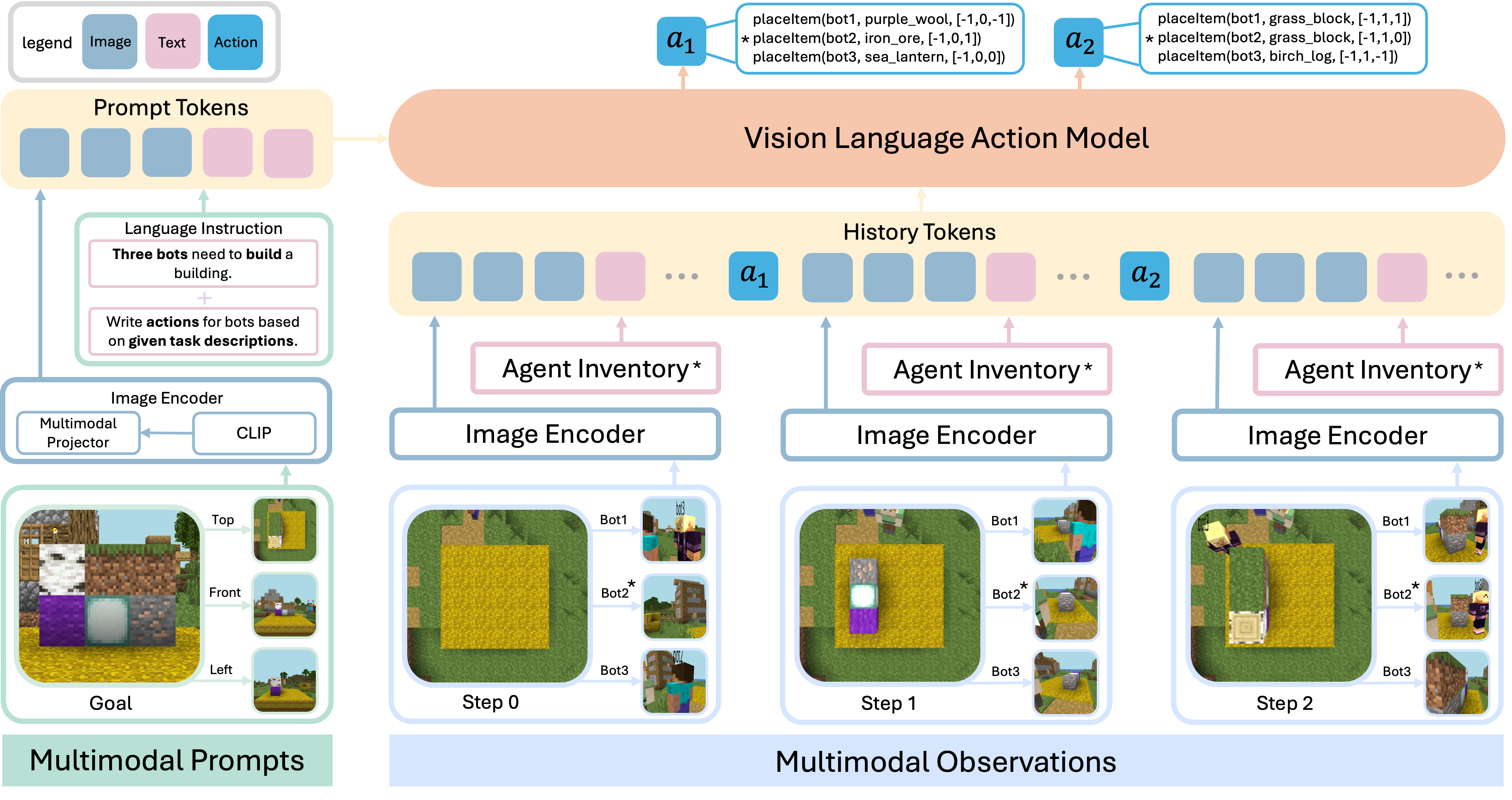
TeamCraft-VLA (Vision-Language-Action) is a multi-modal vision-language action model designed for multi-agent collaborations. The model first encodes multi-modal prompts specifying the task, then encodes the visual observations and inventory information from agents during each time step to generate actions.
Multi-modal Prompts

Multi-modal prompts are provided for all tasks. The system prompt includes both the three orthographic views and specific language instructions. Observations consist of first-person views from different agents, along with agent-specific information.